
 Lingye
Lingye
You publish a careful tutorial, add examples, and still wonder why AI assistant traffic feels invisible. The problem is not always content quality. Sometimes the assistant cannot reach the page, cannot identify the source answer, or sends referrals that your analytics view buries inside generic referral traffic.
Quick Answer
Claude citation work starts with access, not tricks. Your site needs crawlable pages, clear answers, source-backed context, internal paths to deeper material, and tracking that tells you whether AI assistant referrals are appearing. The practical workflow is to confirm that important pages are indexable, avoid blocking relevant Anthropic crawlers, build concise source pages around real questions, add helpful structured data where it matches visible content, publish an llms.txt map only as a supporting file, and create an analytics view for AI assistant traffic. You cannot force the assistant to cite you, and a magic prompt will not replace useful source material. But you can reduce ambiguity: give crawlers permission, give answer engines clean evidence, give readers useful next steps, and review citation gaps monthly.
What This Workflow Is
This AI SEO workflow helps bloggers and small editorial teams build pages that are easier for an AI assistant to find, quote, and send readers back to. It is not a loophole, a ranking hack, or a file that guarantees citations.
The workflow joins five practical checks: crawl access, source-page clarity, internal evidence paths, optional llms.txt mapping, and referral measurement. If you already maintain an AI SEO workflow or an AI Overview citation workflow, this version narrows the task to assistant discovery and citation readiness.
The planning row described this topic as tied to a fast-growing AI referrer. I did not use that phrase as a factual claim because the live source pass did not locate a current primary source strong enough for the headline. The article keeps the reader problem: how to improve citation readiness without pretending that one tactic controls an external assistant.
Who This Workflow Is For
- Bloggers who publish source-backed tutorials and want AI assistant traffic to become measurable.
- SEO editors who need a repeatable checklist before adding another AI visibility tactic.
- Small content teams that already use Search Console, analytics, and internal links but have not reviewed assistant crawler access.
- Site owners who worry that blocking bots, thin source pages, or vague answers may reduce citation chances.
Skip this workflow if the page is not useful for human readers. Citation readiness should improve a real answer page, not dress up thin content.
Tools You Need
- Robots and crawl access review: use the Anthropic crawler documentation and your own robots file to confirm that important pages are not blocked by mistake.
- Google Search Console: use the Performance report to identify pages that already receive demand from question, comparison, and troubleshooting queries.
- Analytics channel grouping: use Google's custom channel group guidance to separate AI assistant referrals from ordinary referral traffic.
- Source-page inventory: list your best guides, definitions, tables, workflows, examples, and source logs.
- Optional llms.txt file: use the llms.txt specification as a map to important markdown-friendly resources, not as a replacement for crawlable pages.
Workflow Summary
| Step | Question | Output |
|---|---|---|
| 1. Confirm access | Can assistant crawlers reach the pages you want cited? | Crawl access notes |
| 2. Choose source pages | Which pages answer real search questions with evidence? | Citation candidate list |
| 3. Build answer blocks | Can a reader understand the answer before the long explanation? | Clear summary and source table |
| 4. Add source paths | Where should the assistant and reader go next? | Internal evidence map |
| 5. Publish support files | Would llms.txt or structured data clarify the site? | Supporting technical notes |
| 6. Measure referrals | Can you see assistant traffic when it arrives? | AI referral review sheet |
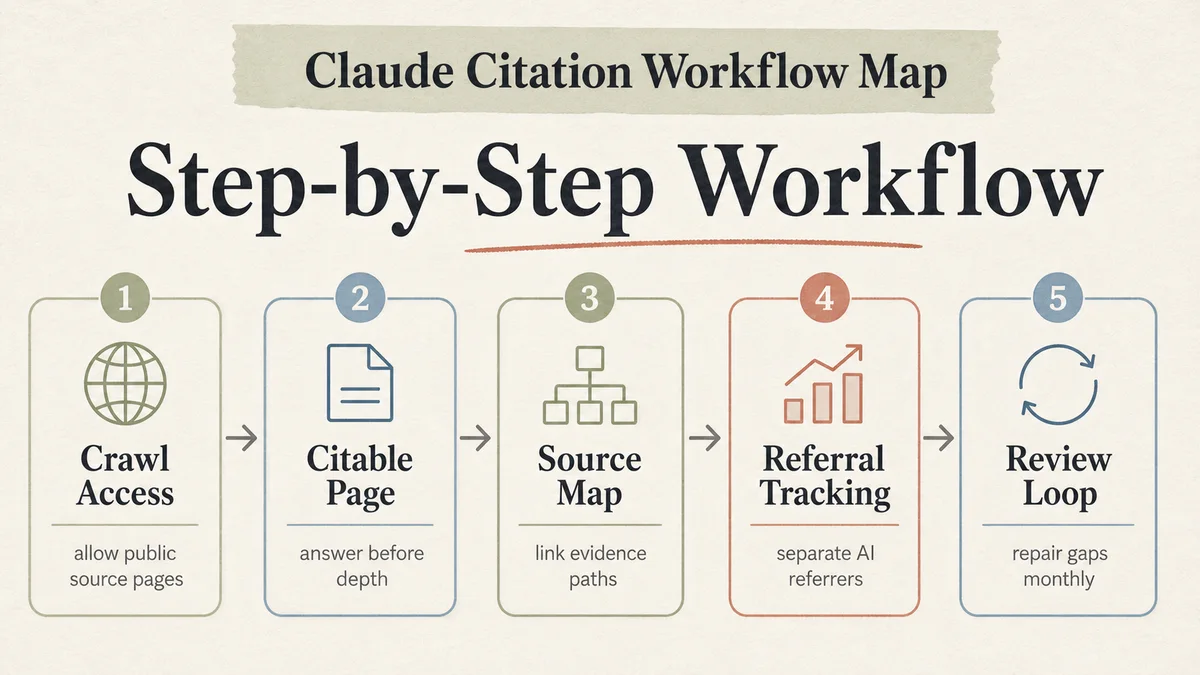
Step-by-Step Workflow
1. Confirm crawl access before changing content
Start with robots rules. Anthropic documents two relevant user-facing/search-facing crawlers: Claude-User, which supports user requests, and Claude-SearchBot, which improves search relevance. If visibility from the assistant matters, review whether your robots file blocks either crawler for pages you want cited.
This does not mean every bot should receive full access. It means the crawl decision should be deliberate. Google's robots.txt guidance is still useful here: robots rules control crawling, not every form of discoverability. Keep sensitive, duplicate, or low-value areas blocked; allow public source pages that support your editorial strategy.
2. Pick pages that already answer real questions
Use Search Console to find pages with question, comparison, and troubleshooting demand. Prioritize queries where the reader needs a workflow, decision table, checklist, or source judgment. Those pages have a stronger reason to earn a citation than a simple definition page.
For MyLingBlog, this is the same editorial filter used in AI search intent analysis: write for the search question people ask before they know your article angle. Do not begin with the tactic. Begin with the reader's uncertain query.
3. Create a citable answer block
Put a direct answer near the top of the page, then support it with evidence, examples, and a next-step artifact. Google's AI features guidance says the same SEO fundamentals still apply and that visible textual content, internal links, structured data that matches the page, and snippet eligibility remain important.
A practical answer block includes the short answer, the scope, the conditions, and the next action. For this article, the answer is not "install one file." It is "confirm access, build source pages, map useful evidence, and measure referrals."
4. Add an internal evidence map
Assistant citations often favor sources that look complete and easy to interpret. Add internal links from the citable page to supporting workflows, definitions, examples, or source logs. Keep the links human-useful. A random hub page does not help a reader or an answer engine understand why the source deserves trust.
For a blogger, a strong evidence map might connect an AI citation page to an AI SEO workflow, a search optimization checklist, and a source-review article. Each link should answer a real follow-up question.
5. Use llms.txt as a map, not a guarantee
The llms.txt proposal describes a markdown file at the site root that can point language models toward useful documentation and resources. It can sit beside robots and sitemaps, but it does not replace normal crawlable pages, internal links, or useful content.
If you add one, keep it short. Link to your best evergreen guides, source pages, API docs, glossary, or methodology pages. Do not stuff it with every post. The point is a curated map, not another sitemap with weaker context.
6. Track assistant referrals and citation gaps
Create an analytics channel group or exploration that separates AI assistant referrers from ordinary referral traffic. Google's own channel-group example shows how teams can group assistant domains together, then move that rule above generic referral rules.
Review the data monthly beside the source-page inventory. If a page gets search impressions but no assistant referrals, inspect access, answer clarity, internal evidence, and whether the topic genuinely deserves citation. If referrals appear, review engaged sessions and reader actions, not only visits.
Copy-and-Paste Prompt
Use this prompt after you gather crawl rules, Search Console queries, and candidate source pages.
Role:
You are an AI SEO editor reviewing whether a blog page is ready to be cited by Claude and other answer assistants.
Inputs:
1. Robots.txt rules for the target site.
2. Candidate page URL, title, opening answer, headings, and internal links.
3. Search Console queries that already lead to the page.
4. Any llms.txt or source-map notes.
5. Analytics referral rules for AI assistant traffic.
Task:
Build a citation readiness review.
For each candidate page, return:
- Reader search question
- Current direct answer
- Evidence or source block present
- Internal source paths available
- Crawl access risk
- llms.txt or source-map support
- Measurement setup
- Missing reason the assistant may not cite this page
- Editorial fix before publication
Rules:
- Do not claim a citation can be guaranteed.
- Do not invent referral traffic or test results.
- Prioritize pages with useful human next steps.
- Reject unsupported growth claims unless a current primary source is supplied.Example Input
| Candidate page | Reader query | Current issue | Observed risk |
|---|---|---|---|
| /ai-seo-workflow | how to optimize blog posts for AI search | Strong workflow, weak source table | Medium |
| /llms-file-for-bloggers | does llms.txt help SEO | Direct answer missing near top | High |
| /ai-referral-tracking | track assistant referral traffic in analytics | Analytics rule not documented | Medium |
| /old-ai-tools-list | best AI tools for bloggers | Too broad and thin | High |
Example Output
| Page | Citation readiness issue | Fix | Do next |
|---|---|---|---|
| /ai-seo-workflow | Answer is useful but evidence is scattered | Add a source table and link to supporting pages | Refresh opening and internal evidence map |
| /llms-file-for-bloggers | Topic answers a direct question but lacks scope | Add answer-first section: what it helps, what it does not do | Publish curated root file only after page update |
| /ai-referral-tracking | Measurement claim is not visible | Add channel group rules and review cadence | Track assistant referrals monthly |
| /old-ai-tools-list | Page is too generic for citation trust | Merge into specific workflows or retire | Stop treating list traffic as citation strategy |
Tested Workflow Notes
The strongest editorial review is not a ranking promise. It is a meeting where each candidate page must explain why an assistant should cite it and why a human reader should continue after the short answer.
- Input type: robots rules, Search Console query export, page headings, internal links, and analytics referrer rules.
- Tool used: Search Console export, analytics channel group, crawl policy review, and source-map spreadsheet.
- Best result: a short list of pages with clear answer blocks, source tables, internal evidence paths, and measurable assistant referral rules.
- What failed: broad tool-list pages, unverified growth claims, and pages that answered the question but offered no next-step artifact.
- Manual edits still needed: source wording, link labels, llms.txt scope, and title/meta alignment with actual search questions.
Pitfalls We've Actually Hit
- Treating llms.txt as a magic switch. It can clarify important resources, but weak pages stay weak.
- Blocking useful crawlers by habit. A copied robots file can block public source pages that the site actually wants discovered.
- Writing for the assistant before writing for the reader. Citation readiness starts with human-useful answers and evidence.
- Using broad trend claims without a source chain. If the growth claim cannot be verified, remove it from the title and explain the workflow instead.
- Tracking only visits. Assistant referrals matter when they send readers who continue, subscribe, compare, or save the workflow.
Common Mistakes
- Adding a root assistant file before fixing the actual pages.
- Publishing a thin definition page for a query that needs troubleshooting steps.
- Forgetting that robots controls crawling and does not guarantee visibility.
- Stuffing internal links into the page without a clear evidence path.
- Listing every article in llms.txt instead of curating the strongest resources.
- Calling referral traffic proof of citation without checking engagement and source path.
Tool Alternatives
You can run this workflow with basic tools: a robots checker, Search Console, analytics, a spreadsheet, and your site editor. A paid SEO suite can speed up inventory work, but it will not decide which pages deserve citation.
If you already have a content refresh process, add this citation-readiness layer beside it. Start with old posts that still earn demand, then update answer blocks, source tables, internal links, and measurement rules. The old-post update workflow is a useful companion when you need to repair existing pages rather than publish from zero.
FAQ
How do I get cited by Claude?
To get cited by Claude, build pages that are crawlable, answer real questions clearly, support claims with evidence, and link to deeper source material. You cannot force a citation, but you can reduce confusion by allowing relevant crawlers, improving answer-first sections, and tracking whether assistant referrals appear.
Does llms.txt help a blog get AI citations?
It can help only as a curated map. The file should point to strong resources, methodology pages, glossaries, or documentation. It should not replace normal SEO basics, internal links, sitemap hygiene, or useful visible content. Treat it as a helpful signpost, not a ranking factor.
Should I block AI crawlers?
Block crawlers from private, duplicate, low-value, or resource-heavy areas if that fits your policy. For public source pages you want discovered, review the relevant bot names before copying a broad block rule. The right answer depends on your content, server capacity, privacy stance, and citation goals.
Why is Claude not citing my website?
The assistant may not reach the page, may not see a concise answer, may find better source material elsewhere, or may not need a citation for that query. Review access, page quality, evidence, internal links, freshness, and whether the query actually needs your source.
How do I measure Claude referral traffic?
Create a custom analytics channel for AI assistant referrers, then review engaged sessions, internal clicks, signups, and returning readers. Do not rely on visits alone. A small number of referrals can be valuable if the page answers a high-intent question and gives the reader a strong next step.
Final Recommendation
Do not chase assistant citations with shortcuts. Build a citation-ready page the same way you would build a trustworthy source: accessible, specific, clear, internally supported, and measurable.
For this topic, the useful artifact is the citation map. Confirm access, choose answer-worthy pages, add source paths, publish support files only when they clarify the site, and measure the traffic that arrives. That is slower than a magic prompt, but it is the path that also improves the article for human readers.



